
 SQL语句
SQL语句
SQL语句
第01章 聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
count
-- 语法
count(column)
column:字段名
-- 功能
计算指定字段在查询结构中出现的个数(不包含NULL值)用于统计非null值的数量
-- 案例
// 计算order_date(不包含null值)这列的数量
count(order_date)
// 计算order_date中是2019年的数量
count(if(year(order_date) = 2019 ,1 ,null))
sum
-- 语法
sum(column)
column:字段名
-- 功能
求和通常适用于数值类型的字段或变量。不包含NULL值
也可用于统计非数值类型的数量,因为sum函数可以对布尔值求和,将true视为1,false视为0
-- 案例
// 计算order_num(不包含null值)这列的求和数
sum(order_num)
// 计算order_date这列中是2019年的数量
sum(order_date like '2019-%')
avg
-- 语法
avg(column)
column:字段名
-- 功能
求取平均值,只适用于数值类型的字段或变量。不包含NULL值
-- 案例
// 计算order_num(不包含null值)这列的平均值
avg(order_num)
max
-- 语法
max(column)
column:字段名
-- 功能
求某一列的最大值,适用于数值类型、字符串类型、日期时间类型的字段(或变量)不包含NULL值
-- 案例
// 计算order_num(不包含null值)这列的最大值
max(order_num)
min
-- 语法
min(column)
column:字段名
-- 功能
求某一列的最小值,适用于数值类型、字符串类型、日期时间类型的字段(或变量)不包含NULL值
-- 案例
// 计算order_num(不包含null值)这列的最小值
min(order_num)
第02章 函数
if
可以增加新的列
-- 语法
if(条件, 条件成立, 条件不成立)
例题

select
*,
if(x+y>z and x+z>y and y+z>x, 'Yes', 'No') as triangle
from
triangle
cast
-- 语法
cast(expression as type)
expression: 目标类型
type:指定类型
type可以是 binary char date datetime time decimal signed unsigned
-- 功能
将任何类型的值转换为指定类型的值
-- 案例
mysql> SELECT (1 + CAST('1' AS unsigned))/2;
+-------------------------------+
| (1 + CAST('1' AS UNSIGNED))/2 |
+-------------------------------+
| 1 |
+-------------------------------+
此案例中的cast就是将字符‘1’作为了无符号整数1
ifnull
可以增加新的列。
ifnull(条件, 条件是空)
-- 例子
// 如果round(sum(a.price * b.units)/sum(b.units), 2)为null则把这列的值变为0
ifnull(round(sum(a.price * b.units)/sum(b.units), 2), 0) as average_price
case then
可以增加新的列。
-- 语法
case
when 条件 then 结果1
else 结果2
end as 别名
例题
-- 解法一
select
x,
y,
z,
case
when x+y>z and x+z>y and y+z>x then 'Yes'
else 'No'
end as 'triangle'
from
triangle;
-- 解法二
select
*,
if(x+y>z and x+z>y and y+z>x, 'Yes', 'No') as triangle
from
triangle
coalesce
-- 语法
coalesce(column, 1)
column: 表中的一列
-- 功能
当column为null值的时候,将返回1,否则将返回column的真实值
-- 案例
select
coalesce(column, 1)
from
tableA
-- 语法
coalesce(column, column1, 1)
column: 表中的一列
column1: 表中的一列
-- 功能
当column不为null,那么无论column1是否为null,都将返回column的真实值
当column为null,而column1不为null的时候,返回column1的真实值
只有当column和column1均为null的时候,将返回1
-- 案例
select
coalesce(column, column1, 1)
from
tableA
窗口函数
注意
窗口函数是MySQL 8 的新特性,MySQL 8 以下版本用不了!
简介
聚合函数是对一组数据计算后返回单个值(即分组)。而窗口函数在行记录上计算某个字段的结果时,可将窗口范围内的数据输入到聚合函数中,并不改变行数。
语法
-- 语法一
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>);
-- over关键字用于指定函数的窗口范围
-- partition by 用于对表分组
-- order by子句用于对分组后的结果进行排序 可以省略
-- 语法二
<窗口函数> over (order by <用于排序的列名>);
-- over关键字用于指定函数的窗口范围
-- order by子句用于对分组后的结果进行排序 可以省略
-- 语法三
<窗口函数> over (order by <用于排序的列名> rows 6 preceding);
-- over关键字用于指定函数的窗口范围
-- order by子句用于对分组后的结果进行排序 可以省略
-- rows 6 preceding表示作用于当前行加上前六行 如果是窗口函数是sum表示意思就是从当前行开始固定求取前6行的值包括当前行也就是7行
常用窗口函数 rank() dense_rank() row_number()
常用聚合函数 max() min() count() sum() avg()
准备表和数据
create table if not exists employee
(
`eid` int not null auto_increment comment '员工id' primary key,
`ename` varchar(20) not null comment '员工名称',
`dname` varchar(50) not null comment '部门名称',
`hiredate` date not null comment '入职日期',
`salary` double null comment '薪资'
) comment '员工表';
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('傅嘉熙', '开发部', '2022-08-20 12:00:04', 9000);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('武晟睿', '开发部', '2022-06-12 13:54:12', 9500);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('孙弘文', '开发部', '2022-10-16 08:27:06', 9400);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('潘乐驹', '开发部', '2022-04-22 03:56:11', 9500);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('潘昊焱', '人事部', '2022-02-24 03:40:02', 5000);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('沈涛', '人事部', '2022-12-14 09:16:37', 6000);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('江峻熙', '人事部', '2022-05-12 01:17:48', 5000);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('陆远航', '人事部', '2022-04-14 03:35:57', 5500);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('姜煜祺', '销售部', '2022-03-23 03:21:05', 6000);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('邹明', '销售部', '2022-11-23 23:10:06', 6800);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('董擎苍', '销售部', '2022-02-12 07:54:32', 6500);
insert into employee (`ename`, `dname`, `hiredate`, `salary`) values ('钟俊驰', '销售部', '2022-04-10 12:17:06', 6000);
分别使用聚合函数sum()和窗口函数sum()来根据部门求和看下两者区别。
聚合函数
select
dname,
sum(salary) sum
from
employee
group by
dname
结果
左边为查询结果,右边为原表。
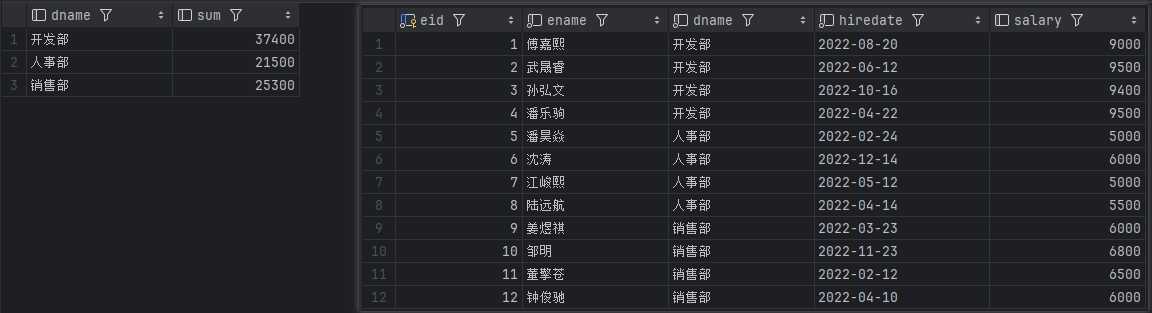
窗口函数
select
dname,
salary,
sum(salary) over(partition by dname order by salary) sum
from
employee
结果
左边为查询结果,右边为原表。
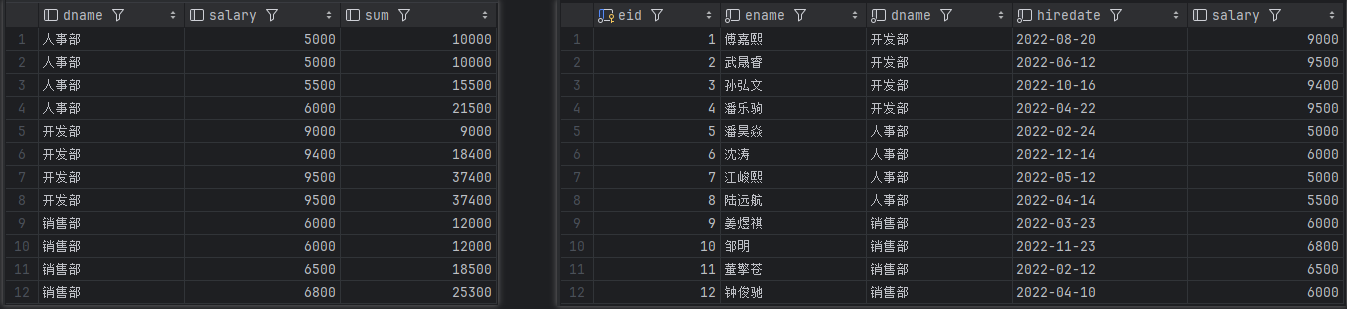
结论
聚合函数是将一组数据计算后返回单个值,而窗口函数在行记录上计算某个字段的结果时,可将窗口范围内的数据输入到聚合函数中,并不改变行数,就好比如我们刚刚根据部门开窗求和salary薪资,每一行的sum数据是将前面范围内的数据都聚合到当前结果中。
字符串系列
concat
-- 语法
concat(Str1,Str2)
Str1: 字符串1
Str2: 字符串2
-- 功能
将两个字符串拼接起来
-- 案例
// 结果为“123456”
concat("123","456")
substring
-- 语法1
substring(Str,Int1,Int2)
Str: 字符串
Int1: 截取的开始位置
Int2: 截取的结束位置
注意:下标开始为1不是0
-- 功能
指定截取字符串的开始位置到结束位置
-- 案例1
// 结果为“1”
substring("123",1,1)
-- 语法2
substring(Str,Int1)
Str: 字符串
Int1: 截取的开始位置
注意:下标开始为1不是0
-- 功能
指定截取字符串的开始位置一直到结束
-- 案例2
// 结果为“23”
substring("123",2)
upper
--语法
upper(Str)
Str:字符串
-- 功能
将字符串全部转化为大写
-- 案例
// 结果为“ABC”
upper("abc")
lower
--语法
lower(Str)
Str:字符串
-- 功能
将字符串转化为小写
-- 案例
// 结果为“abc”
lower("ABC")
char_length
-- 语法
char_length(Str)
Str:字符串
-- 功能
计算字符串的长度不管是数字还是字母都算是一个字符
-- 案例
// 返回 11
char_length("我是TenSoFlow")
length
-- 语法
length(Str)
Str:字符串
-- 功能
计算字符串的长度它的计算单位是字节
utf8编码:一个汉字三个字节,一个数字或字母一个字节。
gbk编码:一个汉字两个字节,一个数字或字母一个字节。
-- 案例
// 如果是utf8编码则返回 15
length("我是TenSoFlow")
group_concat
将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
-- 语法
group_concat([distinct] 字段名 [order by 排序字段 asc/desc] [separator '分隔符'])
三个[]根据需求增加
// 最简便的写法 默认以','分隔
group_concat(字段名)
// 对字段进行去重分隔
group_concat(distince 字段名)
// 对字段进行去重分隔并排序拼接
group_concat(distince 字段名 order by 排序字段)
// 对字段进行去重并以'@'分隔且排序拼接
group_concat(distince 字段名 order by 排序字段 separator '@')
第03章 日期
year
-- 语法
year(date)
date: 日期、时间、或者日期时间类型的值
-- 功能
提取日期中的年份
-- 案例
// 返回2020
year(‘2020-03-04’)
month
-- 语法
month(date)
date: 日期、时间、或者日期时间类型的值
-- 功能
提取日期中的月份
-- 案例
// 返回3
month(‘2020-03-04’)
day
-- 语法
day(date)
date: 日期、时间、或者日期时间类型的值
-- 功能
提取日期中月份的第几天
-- 案例
// 返回4
day(‘2020-03-04’)
limit
-- 语法1
limit row_count
row_count:要返回的行数。
-- 功能
指定只查询前row_count条记录
-- 案例
// 将返回查询结果的前10行。
limit 10
-- 语法2
limit offset,row_count
offset: 跳过的行数
row_count:查询的行数
-- 功能
先跳过offset行,然后再查询row_count行
-- 案例
// 先跳过5行再查询10条数据
limit 5,10
-- 语法3
limit cont offset row_count
row_count: 跳过的行数
cont:查询的行数
-- 功能
先跳过row_count行,然后再查询cont行
-- 案例
// 先跳过10行再查询5条数据
limit 5 offset 10
函数一 datediff
-- 语法
datediff(日期1, 日期2):
日期1:合法的日期表达式 如 '2024-03-04'
日期2:合法的日期表达式 如 '2024-03-03'
得到的结果是日期1与日期2相差的天数。
如果日期1比日期2大,结果为正;如果日期1比日期2小,结果为负。
-- 例子
datediff('2024-03-04','2024-03-03') = 1
函数二 timestampdiff
-- 语法
timestampdiff(时间类型, 日期1, 日期2)
时间类型参数:可以是 day hour second
日期1:合法的日期表达式 如 '2024-03-04'
日期2:合法的日期表达式 如 '2024-03-03'
日期1大于日期2,结果为负,日期1小于日期2,结果为正。
在"时间类型"的参数位置,通过添加"day", "hour", "second"等关键词。来规定计算天数差、小时数差、还是分钟数差。
-- 例子
timestampdiff(day, '2024-03-04', '2024-03-03') = -1
函数三 date_sub
-- 语法
date_sub(date, interval expr type)
interval是“间隙”的意思不是参数是固定语法
date参数:合法的日期表达式 如 '2024-03-04'
expr参数:希望添加的时间间隔
type参数:可以是如下值
MICROSECOND
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
SECOND_MICROSECOND
MINUTE_MICROSECOND
MINUTE_SECOND
HOUR_MICROSECOND
HOUR_SECOND
HOUR_MINUTE
DAY_MICROSECOND
DAY_SECOND
DAY_MINUTE
DAY_HOUR
YEAR_MONTH
函数功能让指定的日期减去指定的天数或者年数等等
-- 例子: 让'2024-03-04'减去两天
date_sub('2024-03-04',interval 2 DAY) = '2024-03-02'
函数四 MIN
属于MySql的聚合函数,可以对日期使用,找到最小日期。
第04章 临时表
with as
简介
WITH 子句,也称为 Common Table Expressions(CTE),是一种在 SQL查询中创建临时结果集的方法,存在于单个语句的范围内,以便在查询中多次引用。它可以使 SQL 查询更加模块化和可读。
-- 使用with语句会创建一个cte_name临时表
with cte_name (column_name1, column_name2, ...) as (
select column1, column2, ...
from table_name
where condition
)
-- 使用cte_name临时表查询
select
column_name1,
column_name2, ...
from
cte_name
where
condition;
第05章 两表连接
准备两表
create table table_a
(
id int(10) not null primary key ,
value varchar(10)
)comment '表A';
create table table_b
(
id int(10) not null primary key ,
value varchar(10)
)comment '表B';
insert into table_a values (1,"福克斯");
insert into table_a values (2,"警察");
insert into table_a values (3,"的士");
insert into table_a values (4,"林肯");
insert into table_a values (5,"亚利桑那州");
insert into table_a values (6,"华盛顿");
insert into table_a values (7,"戴尔");
insert into table_a values (10,"朗讯");
insert into table_b values (1,"福克斯");
insert into table_b values (2,"警察");
insert into table_b values (3,"的士");
insert into table_b values (6,"华盛顿");
insert into table_b values (7,"戴尔");
insert into table_b values (8,"微软");
insert into table_b values (9,"苹果");
insert into table_b values (11,"苏格兰")
表中数据
左边是A表数据,右边是B表数据。
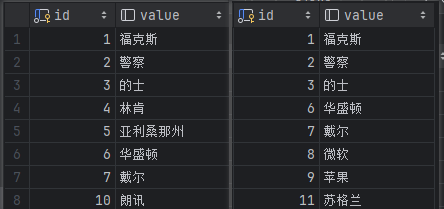
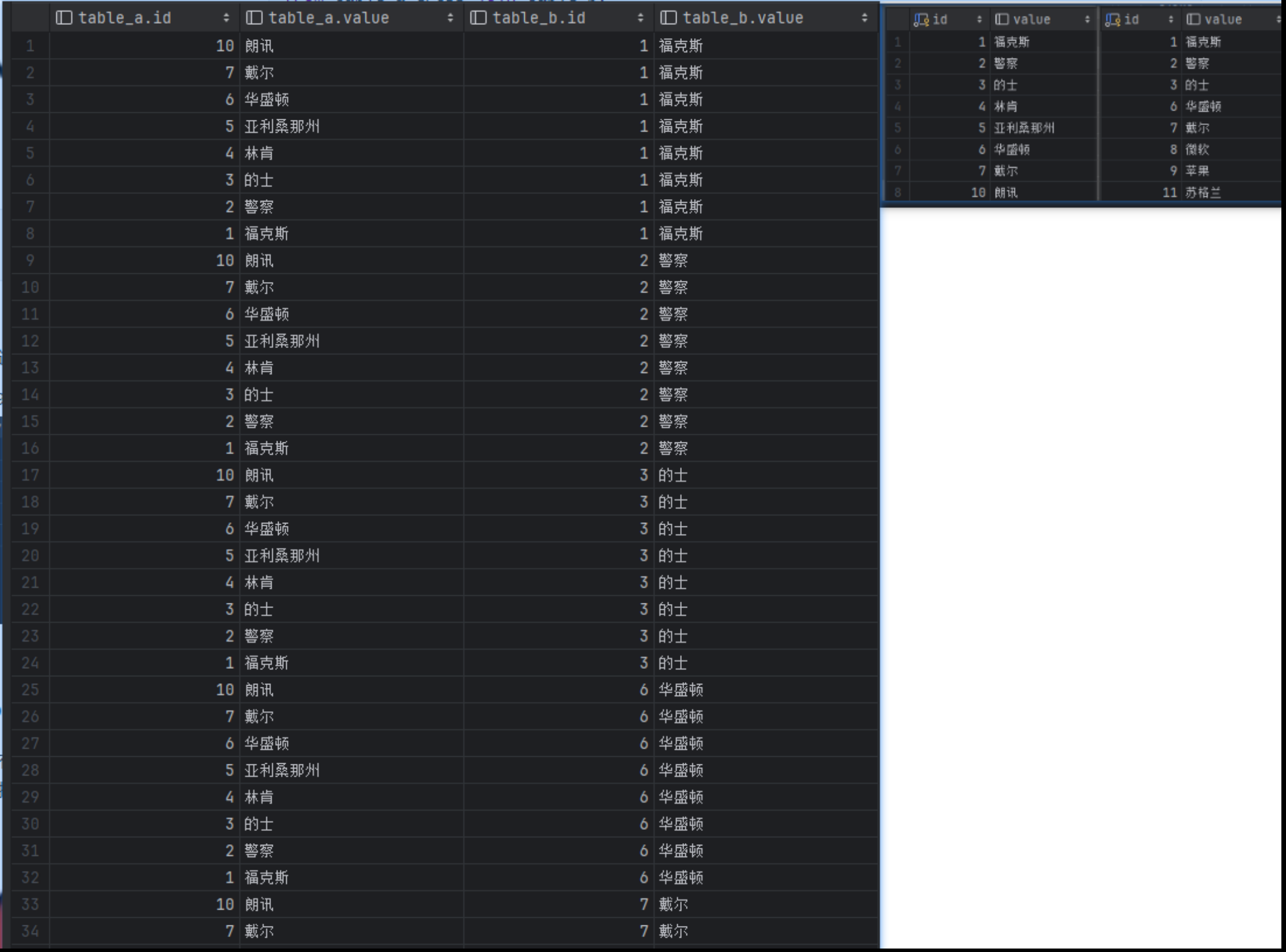
笛卡尔积 cross join
笛卡尔积产生的数量是表A数据的个数乘以表B数据的个数。即表A的每一条数据对应表B的所有数据。
实现代码
select
*
from
table_a
cross join
table_b
查询结果
左边是查询结果(没有显示完全),右边是表A和表B的原始数据。
内连接 inner join
两表都有的才显示出来,就是两个集合的交集。
实现代码
select
*
from
table_a as A
inner join
table_b as B
on
A.id = B.id
查询结果
左边是查询结果,右边是表A和表B的原始数据。
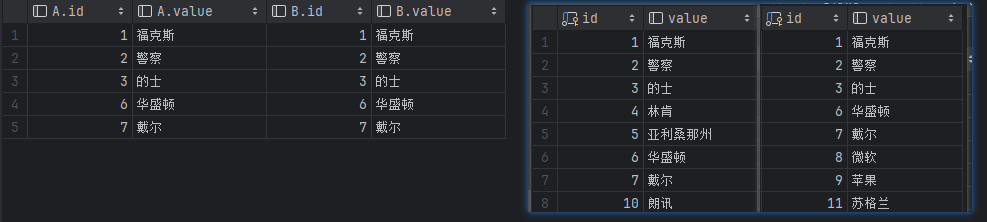
左连接 left join
左连接是左边表的所有数据都显示出来,右边的表数据只显示共同有的那部分,没有对应的部分只能补空显示,所谓的左边表其实就是指放在left join左边的表。
实现代码
select
*
from
table_a as A
left join
table_b as B
on
A.id = B.id
查询结果
左边是查询结果,右边是表A和表B的原始数据。
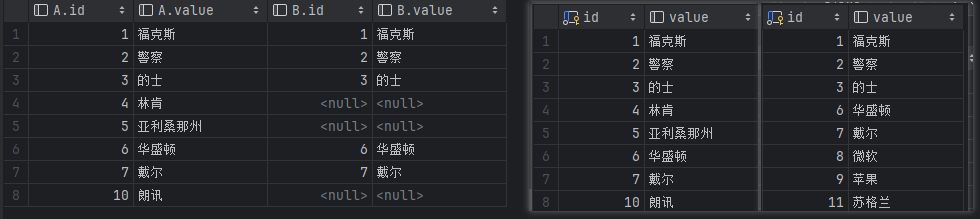
右连接 right join
右连接是右边表的所有数据都显示出来,左边的表数据只显示共同有的那部分,没有对应的部分只能补空显示,所谓的右边表其实就是指放在left join右边的表。
实现代码
select
*
from
table_a as A
right join
table_b as B
on
A.id = B.id
查询结果
左边是查询结果,右边是表A和表B的原始数据。
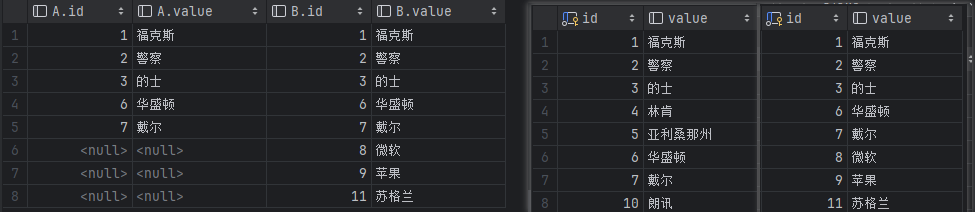
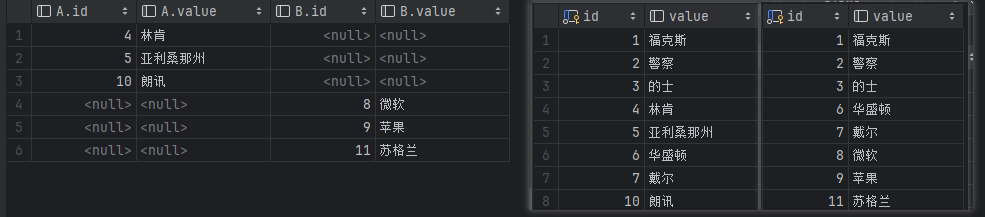
外(全)连接
查询出左表和右表所有数据,但是去除两表的重复数据。
实现代码
# Mysql不支持全连接(outer join),只能用以下代码实现效果,含义是左连接+右连接+去重=全连接:
# union会去除两个查询中重复的行
select
*
from
table_a as A
left join
table_b as B
on
A.id = B.id
union
select
*
from
table_a as A
right join
table_b as B
on
A.id = B.id;
查询结果
左边是查询结果,右边是表A和表B的原始数据。
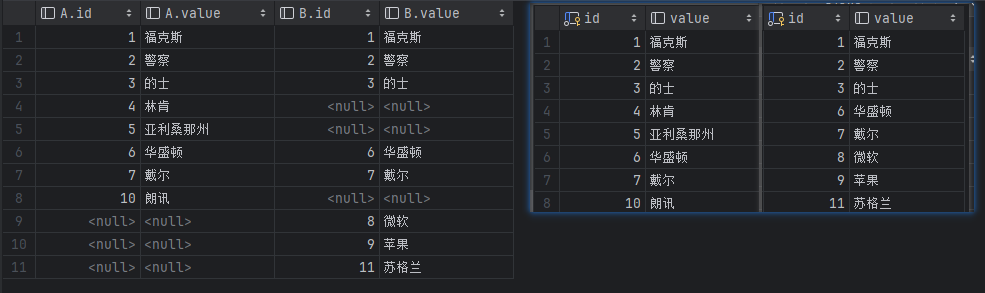
左连接不包含内连接
只查询左边表有的数据,共同有的也查不出来。
实现代码
select
*
from
table_a as A
left join
table_b as B
on
A.id = B.id
where
B.id is null
查询结果
左边是查询结果,右边是表A和表B的原始数据。
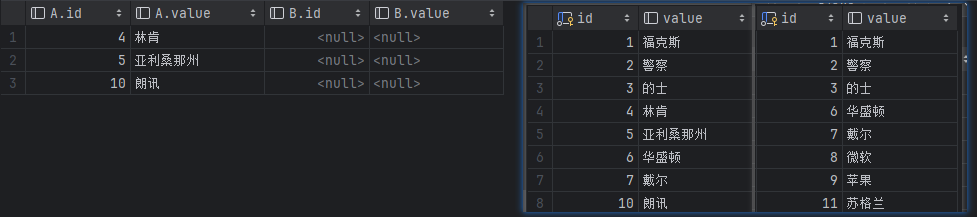
右连接不包含内连接
只查询右边表有的数据,共同有的也查不出来。
实现代码
select
*
from
table_a as A
right join
table_b as B
on
A.id = B.id
where
A.id is null
查询结果
左边是查询结果,右边是表A和表B的原始数据。
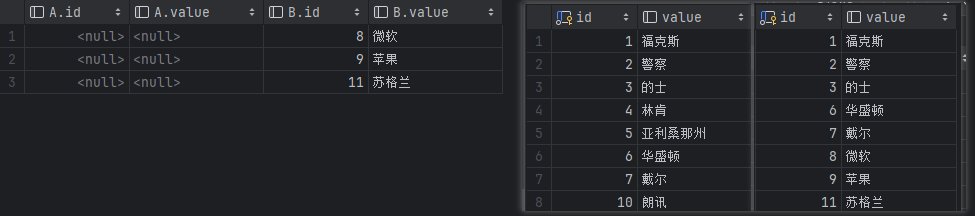
外连接不包含内连接
左右表各自拥有的那部分数据。
实现代码
-- union all 会将两个查询结果合并在一起
select
*
from
table_a as A
left join
table_b as B
on
A.id = B.id
where
B.id is null
union all
select
*
from
table_a as A
right join
table_b as B
on
A.id = B.id
where
A.id is null
查询结果
左边是查询结果,右边是表A和表B的原始数据。
第06章 解决方案
匹配2020年2月份的数据
-- 方案一
where order_date between '2020-02-01' and '2020-02-29'
-- 方案二
where order_date like '2020-02-%'
第07章 经典例题
例题001-经典行转列
题目
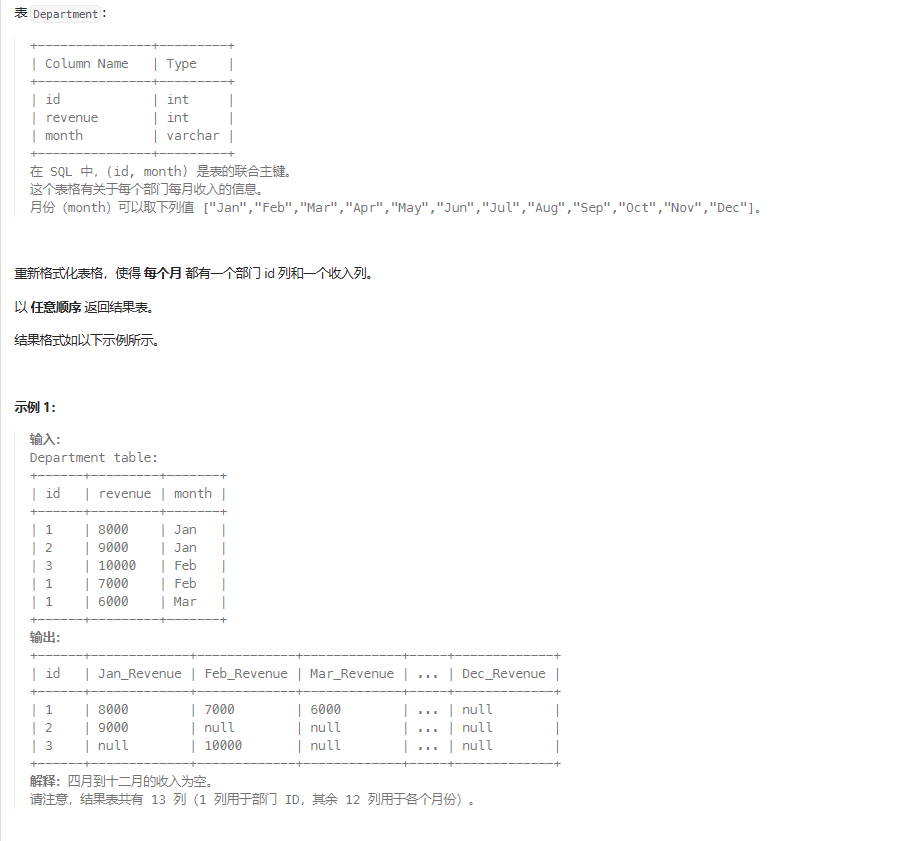
题解
group by的作用:group by id 会使Department表按照id分组,生成一张虚拟表(假想中的表)如下:
| id | revenue | month |
|---|---|---|
| 1 | 8000 7000 6000 | Jan Feb Mar |
| 2 | 9000 | Jan |
| 3 | 10000 | Feb |
在虚拟表中,所有id=1的revenue或者month数据都写在了同一个单元格中,如8000、7000、6000都是写在同一单元格内的。真正的表是不能这样写的,所以这种写法只存在于虚拟表中,帮助我们理解。
case when的原理:当一个单元格中有多个数据时,case when只会提取当中的第一个数据。以CASE WHEN month='Feb' THEN revenue END 为例,当id=1时,它只会提取month对应单元格里的第一个数据,即Jan,它不等于Feb,所以找不到Feb对应的revenue,所以返回NULL。
那该如何解决单元格内含多个数据的情况:答案就是使用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如SUM()或MAX(),而每个聚合函数的输入就是每一个多数据的单元格。简而言之就是遍历。
答案
select
id,
sum(case when month = 'Jan' then revenue end) as Jan_Revenue,
sum(case when month = 'Feb' then revenue end) as Feb_Revenue,
sum(case when month = 'Mar' then revenue end) as Mar_Revenue,
sum(case when month = 'Apr' then revenue end) as Apr_Revenue,
sum(case when month = 'May' then revenue end) as May_Revenue,
sum(case when month = 'Jun' then revenue end) as Jun_Revenue,
sum(case when month = 'Jul' then revenue end) as Jul_Revenue,
sum(case when month = 'Aug' then revenue end) as Aug_Revenue,
sum(case when month = 'Sep' then revenue end) as Sep_Revenue,
sum(case when month = 'Oct' then revenue end) as Oct_Revenue,
sum(case when month = 'Nov' then revenue end) as Nov_Revenue,
sum(case when month = 'Dec' then revenue end) as Dec_Revenue
from
Department
group by
id
order by
id